Disentangled Representation Learning GAN for Pose-Invariant Face Recognition
原文链接
Disentangled Representation Learning GAN for Pose-Invariant Face Recognition. CVPR 2017: 1283-1292
摘要
两张人脸图像之间的较大姿势差异是人脸识别领域的关键挑战之一。本文提出的DR-GAN有三个创新点:第一,除了图像合成之外,生成器的编码器-解码器(encoder-decoder)结构允许DR-GAN学习到生成性的和有辨别性的(generative and discriminative)特征(representation);第二,这种特征和其他的人脸特征(例如姿势)是明确分离的,通过提供给解码器姿势编码(pose code),以及提供给判别器姿势估计(pose estimation)来实现;第三,DR-GAN可以使用一张图片或多张图片作为输入,然后生成一个统一的特征以及任意数量的合成图像。
3. 模型提出
DR-GAN有两个版本:基础模型使用一张图片作为输入,称作single-image DR-GAN,扩展模型对每个对象(subject)都可利用多张图片作为输入,称作multi-image DR-GAN。
3.2. Single-Image DR-GAN
single-image DR-GAN比起以前的GAN有两个创新点。首先,它通过编码器-解码器(encoder-decoder)结构的生成器学习人脸图像的身份特征,其中特征是编码器的输出和解码器的输入。由于特征是解码器的输入,用于合成同一个对象的多个脸,因此它是一个生成性(generative)特征。
其次,在人脸识别中,人脸的的外观上经常存在一些干扰变量(distractive variations),因此,编码器学到的特征可能包含这些变量。例如,对于同一个对象,编码器可能给出不同的身份特征导致生成的两张人脸有0°和90°的偏差(yaw,相当于x,y,z轴中的z轴)。为了弥补这一点,除了类似于semi-supervised GAN的类标签外,我们还使用诸如姿势和照明之类的辅助信息(side information)来明确地理清(disentangle)这些变量,这有助于我们学习到有辨别性的(discriminative)特征。
3.2.1 问题表述(Problem Formulation)
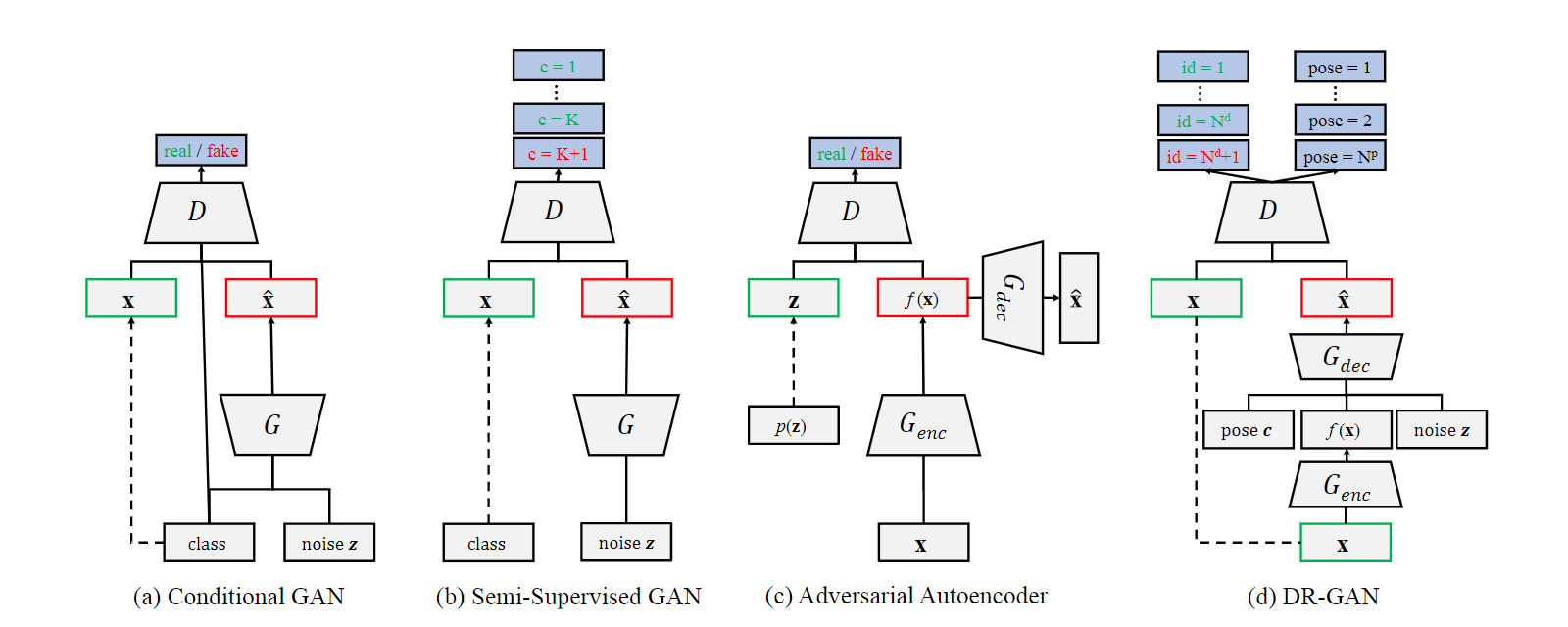
给定一个标签为$\bf y \rm = \it \{y^d \rm , \it y^p\}$的图像$\bf x$,其中$y^d$代表身份(identity)$y^p$代表姿势(pose),我们学习问题的目标是双重的(twofold):1)为PIFR(Pose-Invariant Face Recognition)学习到一个姿势不变的(pose-invariant)身份特征;2)通过一个姿势编码$\bf c$生成一张与$y^d$具有相同身份但是不同姿势的人脸图像$\bf \widehat{x}$。我们的方法是根据原始图像$\bf x$和姿势编码$\bf c$来训练DR-GAN,其结构如Fig. 2 (d)所示。
与传统的GAN中的判别器不同,我们的$D$是一个由两部分组成的多任务CNN(multi-task CNN):$D = [D^d, D^p]$。$D^d \in \mathbb{R}^{N^d + 1}$用于身份分类,$N^d$为训练集中的对象(subject)总数,附加维度用于伪造类别(fake class)。$D^p \in \mathbb{R}^{N^p}$用于姿势分类,$N^p$为离散姿势(discrete poses)的总数。给定一个真实人脸图像$\bf x$,$D$旨在估计其身份和姿势;当从生成器中获得一张合成人脸图像$\bf \widehat{x} \rm = \it G \rm (\bf x \rm , \bf c \rm , \bf z \rm )$,$D$使用如下目标函数尝试将$\bf \widehat{x}$分类为伪(fake):
其中,$D^d_i$和$D^p_i$是$D^d$和$D^p$中的第$i$个元素。式中第一项的目的是最大化$\bf x$被归类为真实身份和姿势的概率。第二项的目的是最大化$\bf x$被归类为伪的概率。
同时,$G$包含一个编码器$G_{enc}$和一个解码器$G_{dec}$。$G_{enc}$旨在从人脸图像$\bf x$$: f(\bf x \rm ) = \it G_{enc} \rm (\bf x \rm )$中学习到一份身份特征。$G_{dec}$旨在合成一张带有身份特征$y^d$并且目标姿势由$\bf c$指定的人脸图像$\bf \widehat{x} \rm = \it G_{dec} \rm (\it f \rm (\bf x \rm ) \it , \bf c \it , \bf z \rm )$,其中$\bf z \it \in \mathbb{R}^{N^z}$代表除了身份和姿势外的其他噪声变量。姿势编码$\bf c \it \in \mathbb{R}^{N^p}$一个目标姿势$y^t$为$1$的one-hot向量。$G$的目标是欺骗$D$将$\bf \widehat{x}$分类为与输入$\bf x$相同的身份和目标姿势,使用如下目标函数:
$G$和$D$在交替训练中相互提高。由于$D$在区分真假图像和分类姿势方面变得更强大,$G$努力生成具有目标姿势的保留身份的人脸来与$D$竞争,这有三个好处。第一,学习到的特征$f(x)$将保留更多有辨别性的(discriminative)身份信息。第二,$D$中的姿势分类(pose classification)使得旋转过的人脸姿势更加精确。第三,通过向$G_{dec}$输入单独的姿势编码,对$G_{enc}$进行训练,以从$f(x)$中分离(disentangle)出姿势变化(pose variation)。例如,$f(x)$应该编码尽可能多的身份信息,但尽可能少的姿势信息。因此,$f(x)$不仅在图像合成上有生成性(generative),而且在PIFR上有辨别性(discriminative)。
3.2.2 网络结构
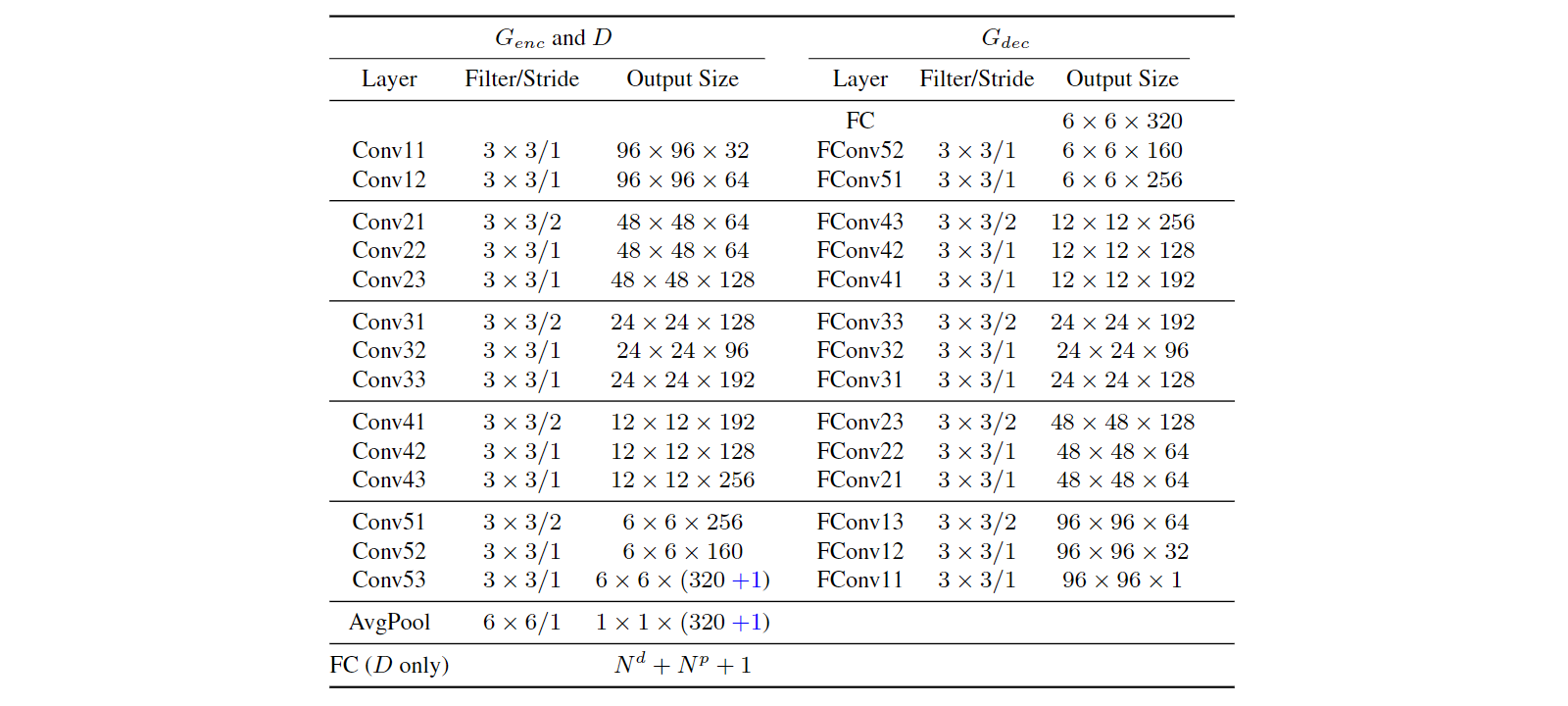
single-image DR-GAN的网络结构如Tab. 1所示,我们对$G_{enc}$和$D$采用了CASIA-Net的结构,其中在每个卷积层后应用批量标准化(batch normalization, BN)和指数线性单元(exponential linear unit, ELU)。$D$被训练来优化Eqn. 4,通过为$(N_d + 1)$个身份和$N_p$个姿势分类添加一个具有softmax损失的全连接层。$G$包含$G_{enc}$和$G_{dec}$,它们被待学习的(to-be-learned)身份特征$f(x) \in \mathbb{R}^{320}$桥接(bridged),这是我们网络中的平均池化层(AvgPool)的输出。$f(x)$与姿势编码$\bf c$和随机噪声$\bf z$连接(concatenate)。一系列的反卷积层(fractionally-strided convolutions, FConv)将$(320 + N_p + N_z)$维的连接向量(concatenate vector)转换成一张合成图像$\bf \widehat{x} \rm = \it G \rm (\bf x \rm , \bf c \rm , \bf z \rm )$,其大小与$\bf x$相同。$G$被训练来最大化Eqn. 5,当一张合成人脸被传给$D$时,梯度(gradient)会被反向传播(back-propagated)以更新$G$。
3.3. Multi-Image DR-GAN
single-image DR-GAN通过处理一张图片$\bf x$提取身份特征并进行面部旋转。然而,在训练过程中,有时是在测试过程中,每个对象通常有多张图像。为了充分利用它们,我们提出了multi-image DR-GAN,对于训练和测试阶段都有好处。对于训练阶段,它可以从多个互补的(complementary)图像中学习到更好的身份特征。对于测试阶段,它可以实现模板到模板(template-to-template)的匹配,这解决了解决了实际监控应用(surveillance application)中的一个关键需求。
multi-image DR-GAN有与single-image DR-GAN相同的$D$,但不同的$G$,如Fig. 3所示。除了提取$f(x)$,$G_{enc}$还为每个图像估计一个置信系数(confidence coefficient)$\omega$,用来预测学习到的特征的质量。对于$n$个输入图像$\{\bf x \it _i \rm \} \it ^n_{i \rm = 1}$,融合特征(fuse representation)是所有特征的加权平均(weighted average),
融合后的特征与$\bf c$和$\bf z$连接,然后传给$G_{dec}$以生成一个新图像,该图像预期与输入的图像有相同的身份。因此,$G$的目标函数总共有$2(n + 1)$项:
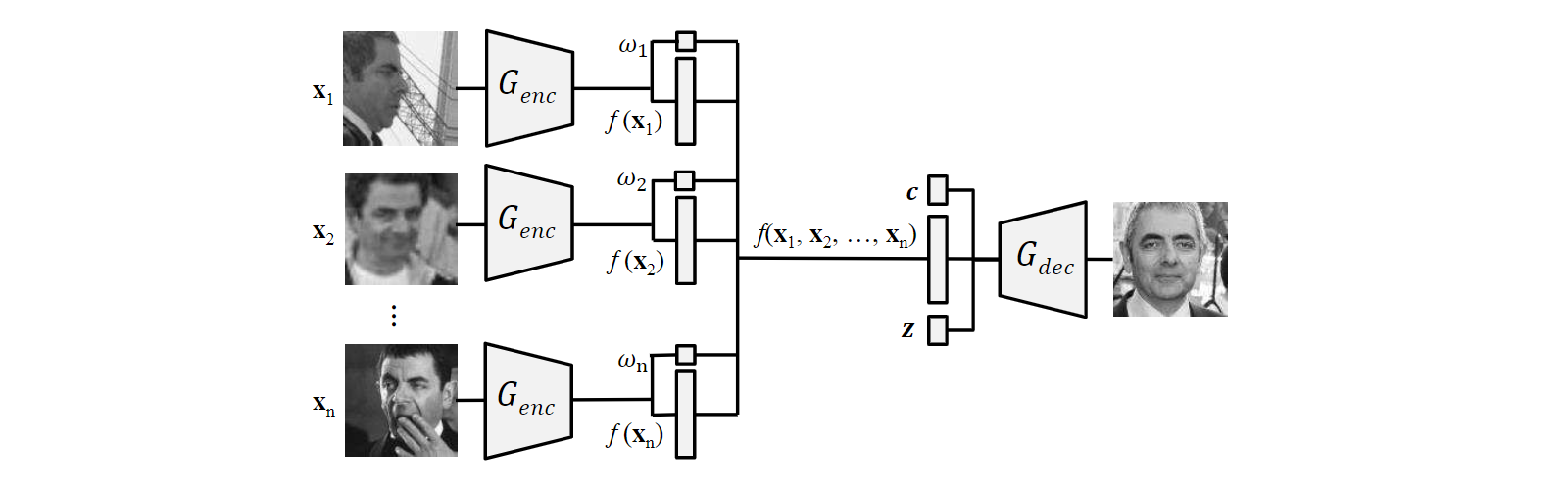
对系数$\omega_i$进行学习,使得质量更高的图片对融合特征的贡献更大。这里的质量可以被视为PIFR性能的指标(indicator),而不是一些低级图像质量指标(low-level image quality)。人脸质量预测是一个经典话题,许多以前的工作试图从后者来估计前者。我们的参数学习本质上是质量预测,与之前的工作相比,选择了新颖的角度。也就是说,在没有明确监督的情况下,它是由$D$通过解码后的图像$G_{dec}(f(\bf x \rm _1, \ldots , \bf x \it _n \rm ), \bf c \rm , \bf z \rm )$驱动,是特征学习过程中的副产品。
注意,每个对象同时训练多个图像,只产生一个而不是多个生成器,即Fig. 3中所有的$G_{enc}$共享相同的参数。这使得通过Eqn. 6和面部旋转(face rotation)进行的特征学习在测试时,可以灵活地获取任意数量的图像。虽然Fig. 2 (d)中所示的网络被用于训练,但我们的测试网络非常简化:只有$G_{enc}$被用来提取特征;$G_{enc}$和$G_{dec}$都用来进行面部旋转。
对于网络结构,multi-image DR-GAN仅对single-image DR-GAN进行了微小修改。具体地说,在$G_{enc}$的末尾,我们在平均池化层(AvgPool)之前的层中添加了一个卷积通道(convolution channel),以估计系数$\omega$。我们使用Sigmoid激活函数将$\omega$限制在[0, 1]范围内。在训练过程中,为了便于图像采样和网络训练,我们将每个对象的输入图片$n$保持不变,尽管这是不必要的。为了模拟输入图像数量的变化,我们使用了一个简单但有效的技巧:对系数$\omega$使用Dropout。因此,在训练时,网络可以接受从1到$n$的任意数量的输入。
3.4. 与先前的GAN的比较
我们将DR-GAN与三个最相关的GAN的变体相比较,如Fig. 2所示。
Conditional GAN:
Semi-Supervised GAN:
Adversarial Autoencoder (AAE):
4. 实验结果
DR-GAN的目标是特征学习和人脸生成。对于前者,我们使用解构出的特征(disentangled representation)作为身份特征,并使用余弦距离度量(cosine distance metric),对受控的和自然环境下的(controlled and in-the-wild)人脸识别性能进行了定量评估(quantitatively evaluation)。对于后者,我们展示了人脸正面话的定性结果(qualitative results)。
4.1. 实验设置
数据集:Multi-PIE是用于评估受控环境中姿势、照明和表情变化下的人脸识别的最大的数据集。按照[45]中的设置,我们使用了337名具有中立表情(neutral expression)的对象,在$\pm60^\circ$范围内的9个姿势,以及20种照明。前200个对象用来训练,剩余的137个对象用于测试。在测试中,每个对象的正面和中立照明(neutral illumination)图像作为gallery,其他图像作为probes。对于Multi-PIE实验,我们添加了一个类似于姿势编码的照明编码来分离(disentangle)照明,因此,我们有$N^d = 200$,$N^p = 9$,$N^{il} = 20$。
对于自然环境,我们在Multi-PIE和CASIA-WebFace上进行训练,并在CFP和IJB-A上进行测试。CASIA-WebFace包括10575名对象的494414个接近正面的照片。我们将整个Multi-PIE(4 sessions, 13 poses, 6 expressions, and 20 illuminations of 337 subjects)添加到训练集中,以提供更多的姿势变化。CFP由500名对象组成,每个对象包含10张正面照片和4张侧面照片。评估方法包括frontal-frontal(FF)和frontal-profile(FP)人脸验证,每个都有10个文件夹,其中包含350个same-person pairs和350个different-person pairs。作为另一个大型姿势数据库,IJB-A拥有500名对象的5396张照片和20412个视频帧。它定义了模板到模板的人脸识别,其中每一个模板都有一个或多个图像。我们将CASIA-WebFace和IJB-A中重叠的27个对象移除。我们有$N^d = 10885$,$N^p = 13$。我们对受控环境和自然环境均设置$N^d = 50$。
实现细节:参考[39],我们将所有人脸图像与标准视图对齐,尺寸为$100 \times 100$。我们从对齐的$100 \times 100$人脸图像中随机抽取$96 \times 96$个区域进行数据扩充。图像强度(image intensities)线性放缩到[-1, 1]。为了给CASIA-WebFace提供姿势编码$y^p$,我们使用了3D人脸对齐[12, 13]将每个人脸分类为13种姿势中的一种。我们的实现是从DC-GAN的一个公开实现中修改而来的。我们遵循了[29]的优化策略。batch size设置为64。所有权重均依据以0为中心的正态分布初始化,标准差为0.02。Adam优化器的学习率为0.0002,动量为0.5。
在传统的GAN中,Goodfellow等人[9]建议优化$k$(通常$k = 1$)步$D$,再优化1步$G$,交替进行。因为$G$变化缓慢,有助于$D$保持接近最优解。然而,在DR-GAN中,由于有类标签,$D$拥有强大的监督能力。因此,在训练后期的迭代中,我们更新$G$的频率比更新$D$的频率高,比如,优化4步$G$,再优化1步$D$。
4.2. 特征学习
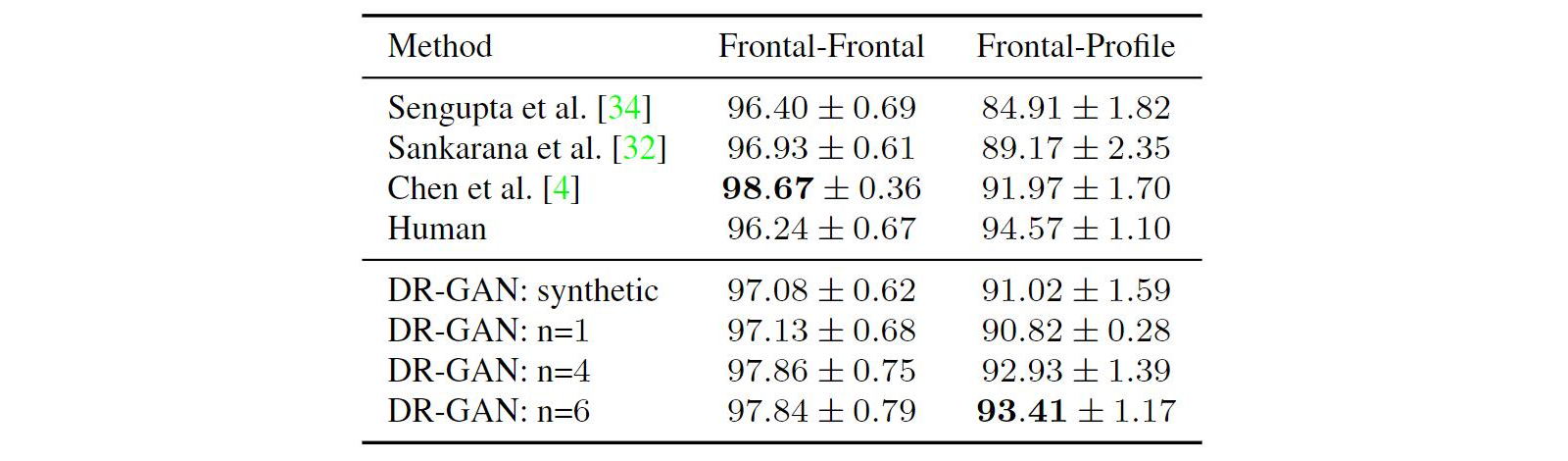
Single vs. Multiple Training Images:我们评估了每个对象的训练图像数($n$)对人脸识别性能的影响。具体来说,使用相同的训练集,我们使用$n = 1, 4, 6$训练了三个模型,其中$n = 1$表示single-image DR-GAN,$n > 1$表示multi-image DR-GAN。使用每个模型的$f(x)$在CFP上的测试性能如Tab. 2所示。我们观察到multi-image DR-GAN相对于single-image DR-GAN的优势,因为在学习$G_{enc}$时有更多的约束,从而可以得到更好的特征。然而,由于计算能力有限,我们没有不断增加$n$。在本文的其余部分,如无特别说明,我们使用$n = 6$的multi-image DR-GAN。
Single vs. Multiple Testing Images:我们还评估了每个对象的测试图像数($n_t$)对Multi-PIE人脸识别性能的影响。我们模仿(mimic)IJB-A生成图像集作为probe集,同时gallery集保持不变,一个对象一张图像。具体地说,我们从Multi-PIE的probe集中选择一个子集$\mathbb{P}_0$,有较大的姿势(large pose)范围($30^\circ$到$60^\circ$),用于形成5个不同的probe集$\{\mathbb{P}_i\}^5_{i = 1}$,$n_t$范围从1到5。首先,我们从$\mathbb{P}_0$中每个对象随机选择一张图像形成$\mathbb{P}_1$。然后,基于$\mathbb{P}_1$,我们通过为每个对象随机添加一张图像的方式构造$\mathbb{P}_2$。我们以类似的方式构造$\mathbb{P}_3$,$\mathbb{P}_4$,$\mathbb{P}_5$。
我们比较了模型和决策度量的三种组合:(i) single-image DR-GAN使用$n_t$张图像的特征的平均余弦距离,(ii) multi-image DR-GAN使用$n_t$张图像的特征的平均余弦距离,和(iii) multi-image DR-GAN使用融合特征(fused representation)的平均余弦距离。如Tab. 3所示,比较(ii)和(iii),使用特征融合网络学习到的系数优于传统的分数平均(score averaging)。有~0.5%的持续改善(consistent improvement)。虽然从(i)到(ii)也有一些改善,但随着$n_t$的增加存在着边际递减(margin decrease)。

Results on Benchmark Databases:我们将我们的方法与最先进的人脸识别方法在Multi-PIE,CFP和IJB-A上进行了比较。Table 4展示了与具有相同设置的方法相比,在Multi-PIE上的人脸识别性能。我们的方法表现出了对大姿势(large pose)范围人脸的显著改进。不同姿势之间的识别率变化比基准小很多,这表明我们学习到的特征(representation)对姿势变化更具鲁棒性。

Table 2展示了在CFP上的比较。结果得出在平均人脸验证精度上的标准差超过10倍。我们在frontal-frontal验证上取得了相当的性能,同时,在frontal-profile验证上有~1.4%的提高。
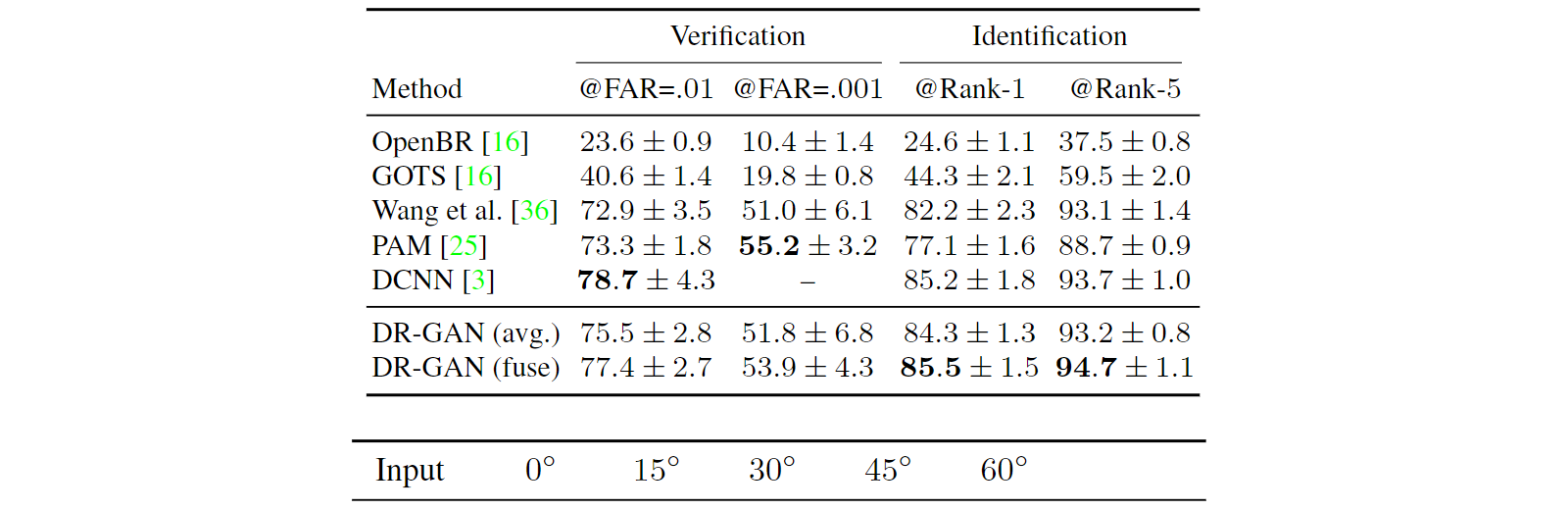
Table 5展示了在IJB-A上的人脸识别和验证的性能。DR-GAN达到了与最先进的方法相当的性能。此外,提出的通过习得的系数的融合方案要优于特征的平均余弦距离。在自然环境下的结果展示了DR-GAN在PIFR问题上的能力。